Nvm Store: 第二届阿里数据库大赛参赛记录
前段时间因兴趣使然,参加了第二届阿里数据库大赛,并成功冲入决赛。 本届数据库大赛的题目是在Intel提供的持久化内存(Persistent Memory)上实现一套KV Store。 持久化内存一直是数据库研究的一个新兴研究方向,十分高兴这次有机会在真正的持久化内存上实现系统并测试。 这里是我们参赛作品的一个介绍。
题目简介
本次数据库大赛的题目是在Intel Optane Persistent Memory上实现一套高性能的KV Store, 访问模式主要是随机访问。由于使用的是持久化内存,要求实现的系统能够持久化数据, 在系统Crash等场景下可以正确恢复。Key的写入要求是原子的,写入失败不能影响旧值。
测试使用16个线程写入随机键值对,每个线程写入大约20M条记录,随后会进行十次混合读写。 混合读写阶段的读写具有热点,以写入过程的时间和混合读写过程中最慢一次的时间作为成绩。 总共提供的PMEM大小是64G,但写入数据量会大于64G(因为有重复Key的写入)。 复赛阶段提供了8G DRAM以供使用。具体的题目描述请参见比赛官方网站的介绍。 我所在的队伍在最后的决赛获得了季军(第四名)。
首先需要介绍一下Persistent Memory,这是一种插在内存插槽上的新兴存储设备, 在数据库领域是一个前沿研究热点。它具有类似DRAM的随机读取能力,但是能在掉电之后保持数据不丢失。 与插在PCI-E/M.2插槽的所谓NVMe SSD不同,PMEM具有更细的访问粒度(8byte字长), 更强的随机访问能力。但我们在测试中发现,它的性能相比DRAM还有一定的差距。
PMEM目前的一种常用配置是将DRAM运行为CPU的L4 Cache,使用单位容量价格较低的PMEM作为主存, 这种方式可以使现有应用程序无痛迁移到PMEM上,且不会相比DRAM有太大的性能差异。 但是想要充分利用PMEM的性能,最佳方案仍然是设计专业的应用程序。 为此,需要使用PMDK等工具直接访问PMEM。 Linux等操作系统也已经位PMEM提供的DAX功能,可以绕过操作系统的页面管理,直接写入PMEM。
本赛题的背景即是如此。对题目的信息进行分析,可以知道:
- 写入数据量大于PMEM空间,说明存在大量的覆盖写,对Allocator的设计要求比较高
- 内存相对来说比较充裕,且PMEM相比DRAM的总体性能还是有一定差距,因此应该尽量将不需要持久化的数据维护在DRAM
- 并发写入的线程数较多,应该尽量使用Thread Local的数据结构,避免线程间同步。 必须要同步的地方使用细粒度锁
此外,在测试的时候发现,本地使用DRAM虚拟的PMEM和硬件PMEM的特性差异较大, 因此需要尽量在实际硬件环境下测试才能得到有意义的结果,不能依赖本地试验结果。
在以上分析的基础上,我们的系统采用了如下设计。
概览
我们设计的系统架构图如下:
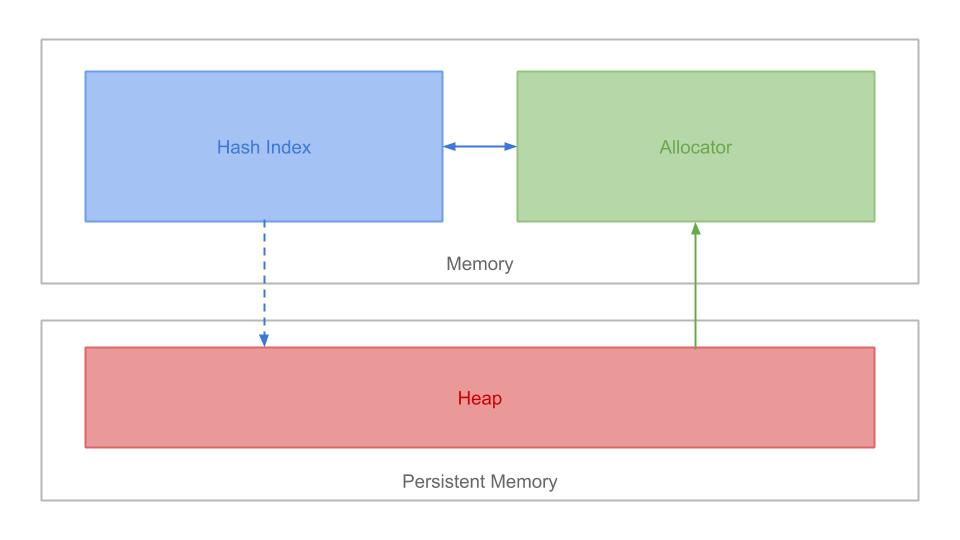
总体来说,系统分为以下三个部分:
- Hash Index:记录Key到Value映射的内存索引,实现查询和更新操作
- Allocator:用来管理Heap上的存储空间,实现空间的分配和回收
- Heap:用于写入数据记录的PMEM空间
KV Store的读写操作都很简单,其中,写入操作使用类似影子分页 (Shadow Paging) 的方法:
- 先使用Allocator分配一块新的Heap空间
- 直接将Record写入新分配的空间
- 更新Hash Index,指向新写入的地址
读取也很简单:通过Hash Index找到Heap上的地址并读取即可。
Heap
堆是存储实际数据的地方,它的设计关系到如何实现写入的持久化、原子性和可恢复性。 同时,写入堆的方式和堆上记录(Record)的写入方法也极大地关系到写入的性能。 下图展示了Heap的大致结构。
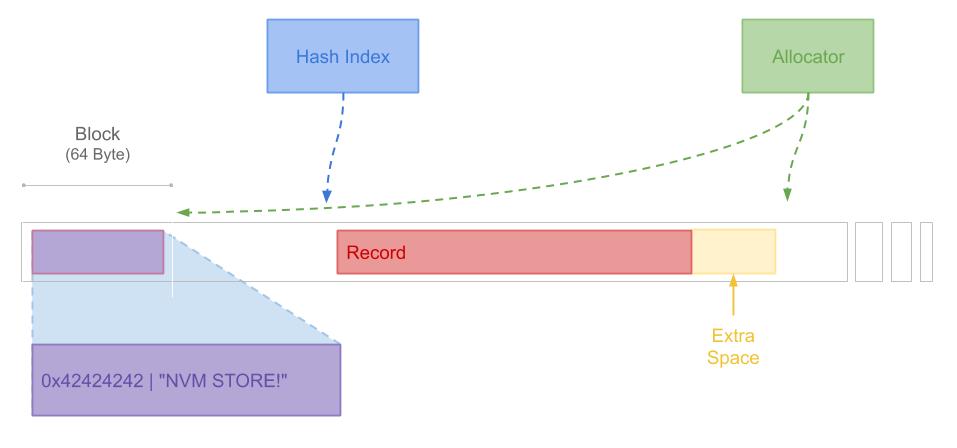
在我们的系统中,Heap被划分为等长的Block,因此Heap内存的分配都是以Block为单位的。 Heap的第一个块用于写入Magic Number。Hash Index当中的Entry指向Record的地址, 而Allocator中会维护Heap中所有的空闲空间的位置。
Record是写入在Heap上的表示,它要记录所写入的Key和Value,并保证可以原子地写入数据并可以恢复。 下图是Record的结构的展示:
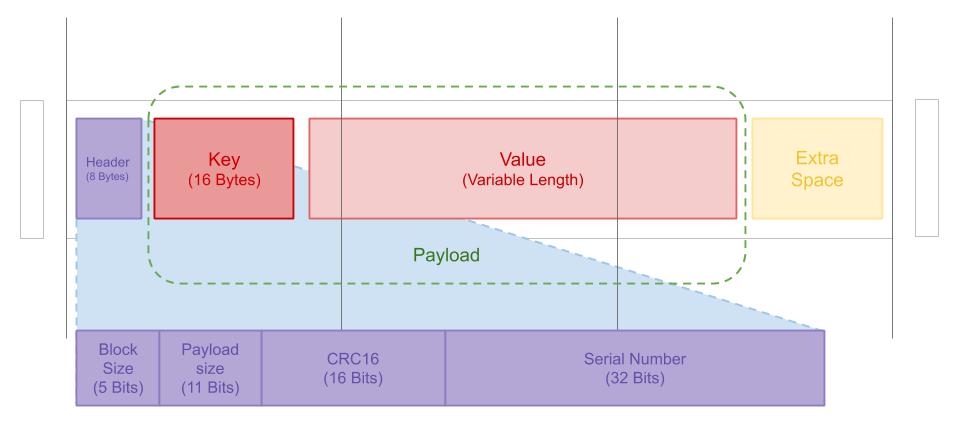
Record由整数个Block构成,在Record的头部是存储元信息的Header,之后是Key和Value组成的Payload, 由于Record总是由整数个Block构成,因此在Record的结尾可能会有一部分冗余空间没有被利用。 Record中最重要的是Header,它的结构包括:
- BlockSize:Record包含的Block的总数量,由于Value的长度小于1024,因此一条记录的总长度 总小于1048(Header+Key+Value),则BlockSize不大于17,可以用5个二进制位表示
- PayloadSize:存储Payload的实际长度,Payload最长不超过1040字节,因此可以用11个二进制位表示
- CRC16:由Payload的CRC校验折叠而成。用于保证Record写入的原子性
- Serial Number:Record的序列号,用于判断Record的先后顺序
在Heap上写入Record的方法是先在内存中组装好一个Record,并写入Header中的字段,
然后使用pmem_memcpy命令的NON_TEMPORAL模式写入。在内存中组装Record的原因,
一方面是内存的访问性能仍然快于PMEM,另一方面是因为可以利用NON_TEMPORAL模式,
使用一次刷写持久化一整个Record。
所谓的NON_TEMPORAL写入,在一些文献中称为Stream写入。简单来说,一般CPU写入一段内存空间时,
会先将对应内存中的一个CacheLine加载到CPU的缓存中,进行修改之后再写回。也就是说,
正常情况下,即使你只在某个位置写入了几个Byte的数据,CPU仍然会把所在的CacheLine读入。
这在很多情况下显然是低效的,因此现代CPU提供了对应的指令,可以实现对CacheLine的直接刷写,
避免读入。PMEM作为一种特殊的内存,也适用于这些概念。
我们发现,使用CacheLine对齐的Buffer组装Record,并利用NON_TEMPORAL写入方式写入PMEM所得性能最高。
这也意味着我们必须将Heap上的Block设置为64Byte大小,并对齐到CacheLine。
虽然有了NON_TEMPORAL写入,仍不能保证写入Record的原子性。在这里
我们要保证写入的一个Record要么完整地写入成功,要么写入失败(不影响旧值)。
这是因为PMEM只能保证对一个字长(8Byte)写入的原子性,即使是一个CacheLine,
它也不能保证一定是整体写入成功或失败的。
因此,我们在Header中集成了CRC:由于Header被压缩在8个Byte,PMEM可以保证它的原子写入, 因此可以通过校验CRC判断整个Record是否合法。
Serial Number的作用则是用来判断Record的写入顺序,比如说有同一个Key,先后写入了两条数据, 第二条数据的值应该覆盖掉第一条。但是因为有内存回收的原因,第二条数据在文件中的位置可能更早, 因此需要它来判断哪一条更新,以避免恢复出旧值。我们在比赛时使用的是简单的线程本地计数器, 为了实现线程间的有序,可以考虑使用时间戳或全局递增计数器来实现,Serial Number也不必要放在Header里。
在本系统中,将BlockSize和PayloadSize分开存储,这是希望一旦一个Record的空间被分配出去之后, 就不再改变这一块空间的大小。也就是说,未来如果有其他不同长度的数据写到这里,BlockSize仍然不变。 这是因为BlockSize改变可能会导致恢复的问题,比如在一个原来长度10的Record所占位置写入长度5的数据, 如果更改了BlockSize并在此时Crash,则恢复进程可能找不到下一条记录的正确位置。 原因是可能出现Header写入成功但内容写入失败的现象。如果此时恢复进程按照Header中指示的BlockSize(5) 来跳转,会跳转到随机数据所在的位置。
以上设计保证了Record的写入原子性和持久性。恢复记录的算法就非常简单:
- 检查PMEM文件的第一个块是否有Magic Number,如果有就开始恢复进程
- 依次读入记录,进行CRC校验,跳过校验失败的Record。将合法的Record登记到Hash Index上(Serial Number较大的胜出)
- 重复以上过程直到处理完所有能读出的Record
Hash Index
Hash Index也是系统设计中很重要的一部分,他的查询性能是KV Store性能的基础, 此外也需要在这上面实现合理的并发控制,保证多线程写入的一致性。我们设计的Hash Index 有如下特点:
- 开放寻址(Open Addressing)
- 线性探查(Linear Probing)
- Record地址使用
uint32表示 - Hash函数使用CityHash
- 细粒度锁
首先,受Google的Flat Hash Map 启发,我们对计算出的Key的Hash值做了如下图所示处理:
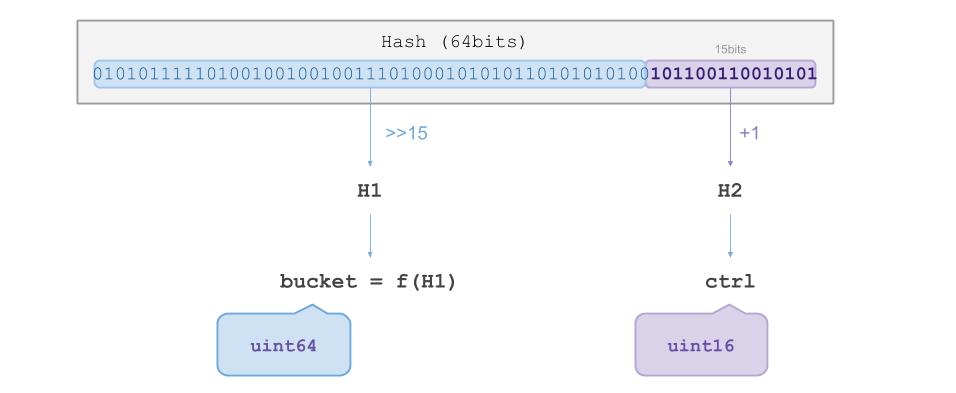
Hash值总共64bit,其中后15个bit被用作H2,剩下的bit被用于H1。H1用来寻址Key应在的Bucket, H2则存放在HashMap的Bucket里。HashMap的Bucket具有如下图所示的构造:
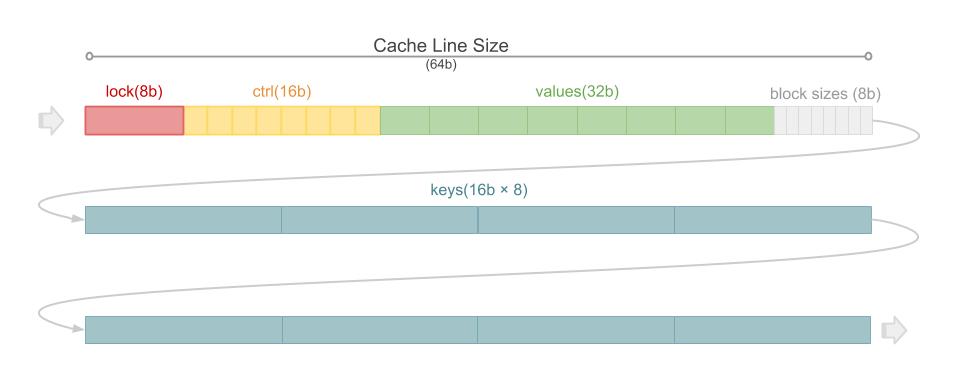
HashMap的一个Bucket是对齐到CacheLine边界的连续三个CacheLine。 每个Bucket可以存放8条记录,从左到右,依次是lock段、ctrl段、value段、block size段和key段。 其中lock段通过原子操作实现细粒度的SpinLock;ctrl段存放8个H2值,用于进行快速比对; value段存放Key对应的记录地址。block size段和key段通过将key和block size缓存在内存中, 避免写入阶段对PMEM的读取。
为什么要设计ctrl段呢?当我们使用H1找到一个Key应该在的Bucket之后,与其逐个比较每个Slot, 不如先使用H2探针来快速判断是否有匹配的Entry。具体来说,可以使用如下流程的SIMD指令, 在少数几个Instruction的操作下,快速以很高的概率查找到匹配的点。
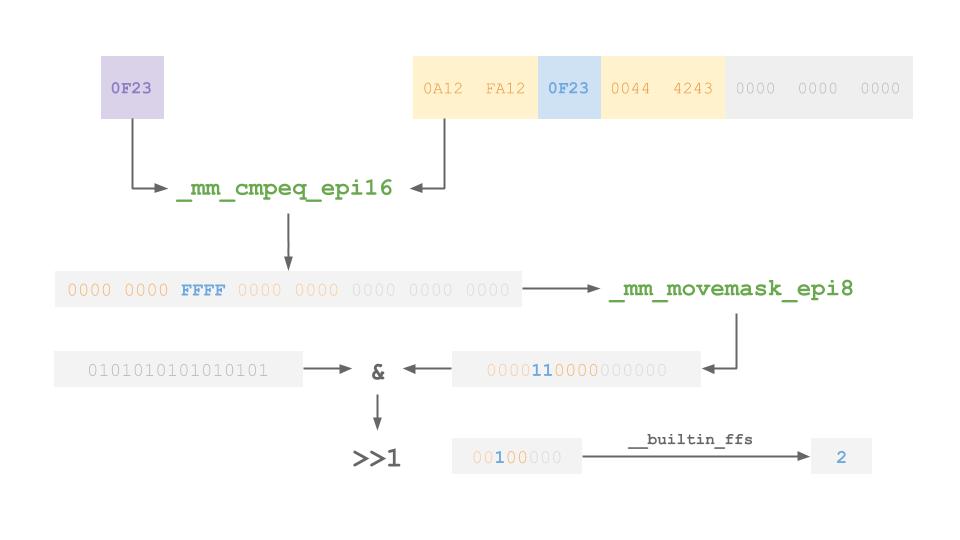
在上述案例中,我们要查找的Key的H2值是0x0F23,在对应的Bucket的ctrl段在slot 2有匹配的值。
通过_mm_cmpeq_epi16和_mm_movemask_epi8指令操作之后,可以快速从16byte的ctrl段找到这个位置。
这里还利用了__builtin_ffs快速求解一个整型数值的第一个1的位置。
利用ctrl段可以减少Hash碰撞的概率和线性探查的长度:
传统HashMap在利用Hash值定位到某个位置后,需要向后逐个对比Key值来找到匹配的Entry,
通常不会存储之后的Key的Hash以供快速检查。使用我们(flat_hash_map)的解决方案,
实际相当于先用Hash的一部分寻找Bucket,再用另一部分进行快速比对,可以更充分地利用Hash值中的每一位。
在使用ctrl段找到一个匹配后,还需要再检查Key以避免碰撞的发生。在一开始的时候,我们的系统会去PMEM上读取Key的值, 后来发现这种混合读写对PMEM性能伤害很大。后来我们采取了将Key缓存在Bucket中的方案,这就是Bucket中的key段的来源。 后来,Block Size也被整合进来,使得无论是写入还是内存回收的时候都不需要访问PMEM,极大地提高了系统的性能。
在本系统的Hash Index的设计中,插入和更新操作会锁定对应的Bucket,由于每个Bucket只有8个slot,所以锁的粒度很细。 在查找操作的探查阶段,我们也不加锁, 这是参考了CLHT的设计, x86系统采用的MESIF protocol具有较强的Memory Order保证, 以及对短于一个字的内存读写的原子性。在查询阶段不加锁,不但可以避免锁等待, 还可以避免查询Miss的情况下对内存的任何写入。实际上,在多核强竞争场景下写入多核共享的CacheLine, 会导致CacheLine同步和核间通讯,因此可能大大降低性能。
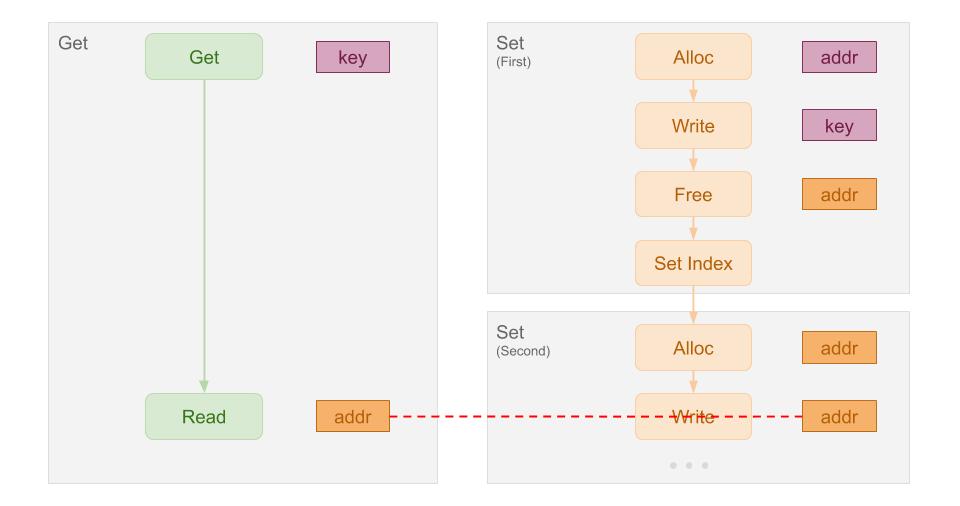
但是值得注意的是,在命中记录开始读取值之前,要锁定Bucket以防止脏读。这是因为在并发线程同时读取一个Key时, 可能出现第1个线程先读到了Key对应记录的地址,第二个线程写入同一个Key,回收了此前的记录, 然后又在第2个写入中利用了这个地址的情况。此时就会出现两个线程对同一段内存的并发读写,触发脏读。 下图展示了这种情况:
Allocator
Allocator是整个系统当中最核心的部分,他的性能和策略设计,直接决定了系统的性能。 在我们的系统中,每个线程都有自己本地的Allocator。Heap空间被预先分配给16个线程。 每个线程的分配策略是先从头开始进行连续写(类似Log-Structured), 随后开始从Allocator记录的空闲空间开始利用,最后使用保留段。基本策略如下图所示:
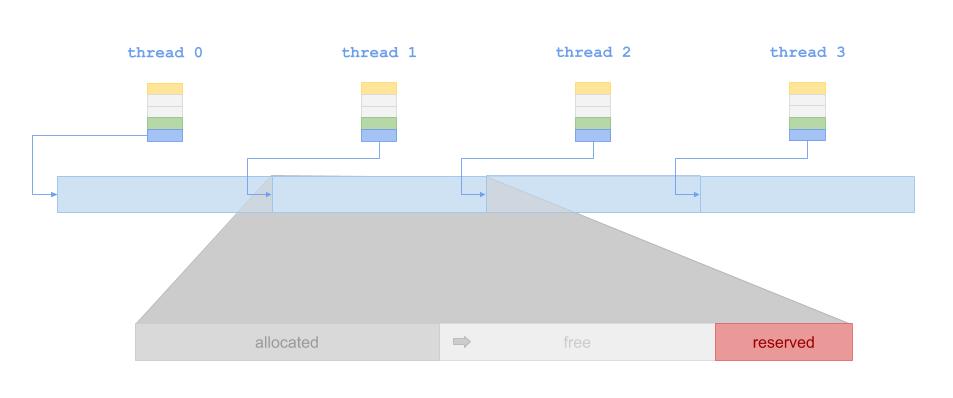
Allocator主要由块状链表组成,不同长度的空闲空间根据它们的Block长度不同,被放置在不同的块状链表中。
每个块状链表的节点存储着一系列空闲空间的地址,并使用一个top指针指向下一个地址存放的位置。
块状链表的块使用next指针相连。为了避免频繁的内存分配,我们对块状链表的块使用了Memory Pool。
使用块状链表的原因是为了在保证Alloc和Free取出和存放地址都是O(1)同时,避免随机内存访问和提高内存利用率。
块状链表比静态分配Stack更灵活。
给定一条记录,我们可以先计算出他所需要的Block数,然后在Allocator中从下到上寻找可以放入这条记录的最小空闲空间。 默认不改变对应空间原来的BlockSize,有可能出现把短记录放在很长的空闲段里,导致空间浪费和OOM, 为此必须要考虑修改长段的长度。在比赛中,我们采用的是在Alloc切分一段空间前,先在后面写入块来维护元数据, 保证恢复进程可以跳转。后来跟其他参赛选手交流后发现,逐块扫描校验CRC也许是一种更好的实现。
下图展示了切分段的解决方法,在将长10的空闲段切开时,先在后面写入一块帮助恢复进程找到跳转位置, 再返回前面的空间。
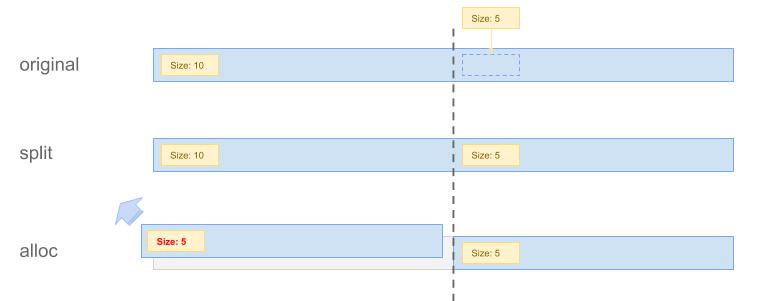
除此之外,我们在Allocator中加入了一个short_alloc字段,
用来在上述情况中,将长段的第二部分放在Allocator的头,在alloc的时候优先检查它。
由于大部分写入的值长度都比较短,因此大概率short_alloc当中的空间会被立即使用,
之后如果有剩余的空间仍然放在short_alloc里,因此可以获得局部的连续写入。
上面提到,分配给每个Allocator管理的段在末尾还有一段保留段。 这是因为有切分块的存在,上述策略对短块友好,因此Heap会越切越细。 如果有长记录的写入到来,可能会出现找不到连续长空间的问题。 为此增加一段保留段,在Allocator分配不出长空间时启用保留段, 避免OOM。
总结
我们首先实现了PMEM上高性能KV Store的基础框架,它具有以下特性:
- 保证了写入的原子性和持久性
- 实现了基于SIMD指令快速查找和细粒度锁的Hash Index
- 实现了简单高效且适应性强的Allocator
在第一阶段我们实现了大约54秒的测试成绩。之后我们将Block Size和Key信息缓存在Hash Index 中,使得写入和Free空间时无需读取PMEM,立即使得成绩提升了8秒到达46秒左右。
最后我们尝试了在内存中组装Record,使用64byte的Block,
并对齐到CacheLine。再配合NON_TEMPORAL写入模式,达到了我们的最佳成绩36秒。
这一成绩距离第2名和第3名的成绩差距不到1秒,应该说是一个级别的实现方案了。 综合来看我们的方案在实现并发控制、持久化和原子性方面的细节方面是比较周到的:
- 使用了CRC校验保证记录写入的完整性
- 使用细粒度的Hash Index锁保证并发性能
- 使用Serial Number保证记录的恢复顺序
- 对切分块场景下的恢复提出了合理的方案
个人认为我们的方案没有特别地利用测试程序的访问模式,通用性非常好。 虽然没有能够拿到更好的名次,总体来说还是非常令人满意的。
在本方案的基础上,参考其他队伍的解决方案,我觉得还有以下一些可以提高的地方:
- 使用HugePage或使用预热TLB的方法来减少Page Fault。有其他参赛选手通过预热TLB获得了可观的性能提升, 但是我觉得在实际生产环境中配置HugePage来减少页表大小是更好的手段。在比赛时有考虑过相关实现, 遗憾的是发现HugePage在测试环境中无法激活后我就放弃了这个方向
- 实现内存碎片整理。目前的解决方案会出现不断碎片化的问题,被切碎的空间即使相连也不会互相合并, 这主要是考虑到实现的复杂性和性能问题。在实际生产环境中,有必要添加内存碎片整理机制,定期合并碎片以获得连续段
- 增加写入的连续性。事实表明,顺序写入PMEM相比于随机写仍然有相当可观的性能提升。 冠军队伍通过利用这一特性获得了超过我们数秒的提升。然而遗憾的是,冠军队伍的实现利用了测试程序访问模式的弱点 (先写入的记录会先被覆盖,因此前段的空间大概率会有连续空闲段)。实际工作负载中是否有此模式是存疑的, 而且冠军队伍的实现在空闲空间不连续的情况下会退化成线性扫描,我相信这方面仍然是可以提高的
参赛感想
这是我第一次参加类似的编程竞赛,很高兴最后能拿奖。特别是在比赛的过程中还学到了很多东西: 在比赛前,我对C++编程语言、内存模型、Memory Order、并发控制等的了解都比较肤浅,在这个比赛中, 我了解到很多内存管理和编写高性能应用的知识。比如:在此之前, 我从来都没有想过内存对象在内存中的地址会对软件的性能产生巨大影响,对齐到CacheLine之后竟然能获得数十秒的性能提升。 也没想过存在于同一CacheLine的两个锁竟然会有False Sharing,两个线程分别对这样的两个锁加锁, 竟然会互相干扰并导致性能退化!可以说涉及到系统调用、TLB、指令集和CPU Cache级别的性能优化技巧让我大开眼界。
编写如此接近硬件的程序让我对C++(以及其他系统编程语言)和高性能编程产生了浓厚的兴趣。 希望未来还可以在这个方向上继续学习。
最后,我们实现的KV Store在Github上开源,以供参考。