分布式索引设计实验 in Go
作为一个 Go 语言门外汉,这段时间刚刚使用 Go 实现了一个分布式索引系统的仿真实验, 这篇文章就来总结一下实现过程和经验。
分布式储存的索引技术是分布式储存的一个技术重点,为了验证一种索引的设计, 自然要设计一个仿真测试来验证各项性能指标是否令人满意。
在实现系统之前,我对 Go 语言的认知水平还很初级,选择并不熟悉的 Go 语言作为实现语言的原因主要由以下几条:
- Go 语言有比较方便的包管理方案,譬如使用
go get命令和第三方的 godep 包来实现依赖管理非常方便。在实验中因为要使用第三方的 B+ Tree 实现,因此 Go 语言成为了一个很好的选择 - Go 语言有出色的编译和执行速度。作为一种编译执行的语言,既能像脚本语言那样获得这么好的编译速度, 又可以获得较好的执行效率,这对于一个要填充较大数据量的仿真实验来说是一个相当吸引人的特性。
- Go 语言的语法相对简洁又不失强大。虽然最初接触时,感觉 Go 语言的语法比较纠结。 但是相比起来要比 C++ 简洁很多,功能反过来又比 C 更为丰富。带有垃圾回收的特性使其最终脱颖而出。
下面详细介绍系统的设计。
Problem Description
在介绍我设计的系统之前,先介绍一下问题以及对应的需求。同时,在这一步还会尽可能地将问题简化。
假定我们有一个由 $n$ 个储存节点组成的分布式储存系统,每个节点分别储存了总体数据的一部分。 随后有一段连续的查询请求,这些查询请求可能随机访问系统中的任何一个节点。 如果被请求的节点当中不包含这个数据,那么它要负责到对应的节点中去寻找数据并返回给客户端。
一个简单的双层索引的设计是:每个节点都有一个 Local Index 和一个 Global Index。 在接收到查询之后,先在 Local Index 当中查找,查找失败之后,再在 Global Index 中查找可能包含目标数据的节点。 此外我们还希望,如果一个查询多对应的目标数据在整个系统中都不存在,那么应该尽可能早的发现, 从而避免转发查询这个成本较高的操作。所以在双层索引中,我们希望在查找 Global Index 的时候, 就可以尽可能确定查询的目标数据是否存在。
一般用 False Positive 这个指标来衡量上述需求。所谓 False Positive,简单来说可以认为是一个系统中不存在的数据, 在 Global Index 当中查询的时候认为他是存在的。Global Index 最直接的设计就是把每个节点的 Local Index 原封不动地放在一起。这种方法可以保证没有 False Positive,但是却要占用较大的空间, 必须要进行一定的 Trade Off,使得在空间可以接受的范围内实现尽可能低的 False Positive 值。
此外还要求查询 Global Index 的查询成本要远少于 Local Index, 在这种情况下,我们可以把双层的索引模型改为总是先查找 Global Index,决定所在节点之后,再查找 Local Index。
为了简化问题,整个测试的系统中储存的数据看成是静态的。也就是说,实验的步骤是先将所有的测试数据插入系统, 再执行测试查询。测试过程中,也不考虑为数据建立冗余备份等问题。
Model
在我设计的系统中,使用的三个重要的模型和数据结构分别是:
- Fat Tree
- B+ Tree
- Bloom Filter
下面分别介绍这几个模型及其作用。
Fat Tree
Fat Tree 并不是什么储存数据的数据结构,而是一种常见的网络拓扑模型。 为了计算搜索请求从一个服务器转发到另一个服务器的时间消耗,就可以使用 Fat Tree 这种结构。
将 Fat Tree 称为树其实有点不准确,他其实更像是一种星型的网络。一个三层的 Fat Tree 结构包含核心层、 聚合层和边缘层三个层次,都有路由器构成。设 Fat Tree 中的每个路由有 $k$ 个端口, 我们把边缘层的每个路由的端口一半用来连接主机,一半用来链接聚合层。同时把 $\frac{k}{2}$ 个边缘层的路由与 $\frac{k}{2}$ 个聚合层的节点放在一起,构成一个完全二分图,称之为一个 Pod。 每个聚合层的路由和 $\frac{k}{2}$ 个核心层的节点链接,同一个 Pod 中不同的聚合层路由连接的核心层路由是不重复的。 显而易见,我们需要 $\frac{k^2}{4}$ 个核心层路由,可以连接的主机总数是 $\frac{k^3}{4}$ 。
由以上方式构造出的网络,有一个特点是每个路由的 $k$ 个端口都被利用了。整个网络中,任意两个主机之间通信, 经过的边数只有三种可能:
- 同一个边缘层路由所连接的主机之间需经过 2 条边
- 同一个 Pod 不同边缘层路由所连接的主机之间需经过 4 条边
- 不同 Pod 中的主机之间需经过 6 条边
一个 $k=4$ 的 Fat Tree 的例子如下图所示:
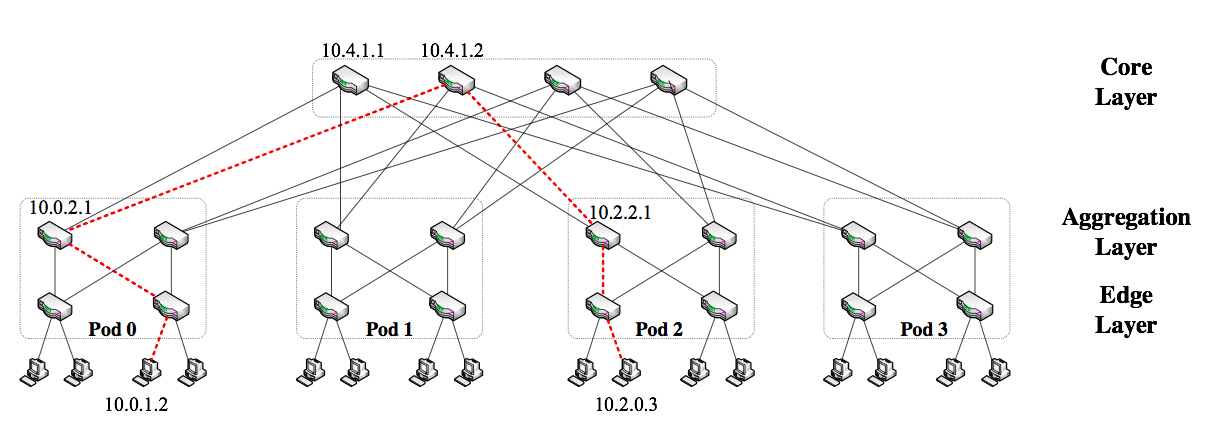
将主机从左到右编号,给定 $k$ 、通信发起节点 a 和目标节点 b,用 Go 编写的计算跳转次数的函数如下。 因在我们的系统中,b 要把查找结果返回给 a,因此所有的路由次数都乘了二。
1 | func TransferCost(k, a, b int) int { |
B+ Tree
关于 B+ Tree 的内容不用赘述了,它是一种常见的索引结构。 它用于储存 $n$ 个元素的空间复杂度是 $O(n)$,插入、查找和删除的时间复杂度都是 $O(\log_b n)$, 是一种非常有效率的索引方式。
前面说过,之所以选择 Go 语言来编写这个实验,一个重要的原因就在于 Go 方便的依赖管理机制,
你可以直接使用托管在 Github 等处的代码,只需要使用go get命令将代码抓取过来即可。
在这里,我使用了 cznic/b 这个第三方库。
1 | go get github.com/cznic/b/ |
在本文中只使用了一个依赖关系,但是对于有多个依赖的项目,我们可能需要一个类似于 Python 的 pip 或者 ruby 的 gem 这样的工具。更近一步,为了隔离不同项目的环境,一个类似 ruby bundle 的工具将会极大地提高生产力。 gpm 和 gvp 搭档使用是一个比较好的解决方案。
我使用 B+ Tree 作为实验中每个节点的 Local Index,为了计算查询 B+ Tree 的计算成本,
可以充分利用 Go 语言提供的函数式编程的能力,使用闭包获得上下文环境来统计比较次数。
cznic/b这个 B+ Tree 实现允许传入一个函数作为比较 Key 大小的函数。我使用了下面的结构体定义一个 Node 。
1 | type Node struct { |
用下面的方法来初始化一个 Node 及其 B+ Tree。
1 | n := new(Node) |
得益于 Go 支持匿名函数以及闭包,我们能够比较优雅的实现这个功能。
Bloom Filter
在 Global Index 这里,我选择了一个非常简单的解决方案:Bloom Filter。 简单来说, Bloom Filter 就是在插入数据时使用 $k$ 个不同的哈希函数,把一个 Key 映射到一个整型数组上的不同的位置, 并将对应的位置标记为1。在查询的时候,对请求的键使用相同的哈希函数进行哈希,检查对应的 $k$ 个位置是否都为 1。 如果是的话,键对应的就值很可能存在,否则一定不存在。
为了节省空间,我们以单个二进制位为单位进行标记,设数组中的所有Int元素共有 $m$ 个比特位,储存的数据共有 $n$ 个,
那么理论上对 Bloom Filter 查询的 False Positive 概率的估计公式为:
$$\left(1-e^{-kn/m} \right)^k$$
从上面的公式可以看出,Bloom Filter 虽然有实现简单、占用空间小的优点,但是储存的数据量越大,False Positive 的概率越高, 过滤的效果也越差。同时,Bloom Filter 对于删除元素的操作没有很方便的处理方法, 在删除时维护 Bloom Filter 的复杂度比较高。
在不考虑删除元素的情况下, Bloom Filter 还是很好的一个选择。 而且 Go 语言的标准库中,已经提供了 MD5、SHA1、ADLER32 以及 CRC64 等哈希算法的实现,只需 import 进来即可使用, 非常方便:
1 | import ( |
测试数据的生成及文件读取
为了测试我们设计的系统的性能,需要生成一些特定分布的测试数据以及对应的查询数据。 两种比较常用的分布是均匀分布和 Zipf 分布。 特别值得一提的是 Zipf 分布,包括英语中单词的出现频率在内,很多重要的数据都服从这一分布。 因此在搜索引擎使用的关键词索引系统中就应该特别重视这种分布。
为了简化问题,这里采取了事先生成一批两种分布的测试数据,在测试的时候依次读出并插入索引的方案。 测试数据都是整型数字,并且作为键插入到 B+ Tree 中。使用 Python 中的 numpy 库生成特定分布的随机数据的方法如下:
1 | import numpy as np |
将生成的数据保存成文本文件,接下来只要在 Go 程序里读取出来就好了。作为一个 Python 重度用户,
在这里我很想使用类似 Generator 那样的语法,让函数每次输出一个文件中的数字。 Go 语言虽然没有yield那样的语法,
但是可以通过 channel 和 goroutine 来实现相近的功能。写出来是像下面这样:
1 | func iterFile(filepath string) chan uint64 { |
值得注意的是defer fi.Close()这行,defer关键字生成的指令会在当前 goroutine
结束的时候执行,避免忘记释放文件的问题,是一个很优雅的语法。
更方便是,我们还可以可以使用for循环来不断从 channel 中取数值。
1 | for i := range iterFile("somefile.txt") { |
在研究 channel 的时候,我发现尽管在函数中可以同时返回多个值,但 Go 语言中并没有元组这样的类型。
所以也就不能建立一次传输多个值的 channel (除非使用interface{}),这也算关于 Go 语言的一个小细节吧。
进行仿真实验
为了均衡各个服务器储存的数据量,可以先对要插入的键进行哈希处理, 再根据哈希过的值决定存放在哪个节点。这样可以很好地将 Zipf 这样密度分布不平衡的数据均匀的分散开。 接下来就可以进行仿真实验了。
对均匀分布和 Zipf 分布的数据进行 100000 次查询的仿真结果如下:
1 | * Testing Uniform Distribution Sparse Set |
总结
这篇文章总结了我最近实现的一个简单的分布式索引仿真测试的程序。 当前的系统设计其实过于简单了,譬如没有考虑到数据的冗余备份等问题。但是总体来看对于两种分布, 系统的表现还是令人满意的。
在实现程序的过程中,我对 Go 语言的一些方面有了更多的了解。 在我看来, Go 语言是一种很有前景的语言,也许在一些场合下仍然无法取代 C,但是相比起来 C++ 似乎不再有竞争力。 当然,Go 现在还缺乏一些 GUI 库、科学计算库等等,不过我相信随着时间的流逝它会展现出越来越强的生命力。