A Brief Intro to Functional Programming
近期受邀在 VMWare 上海的一个公开活动里做了一个技术分享介绍 Functional Programming, 在准备 Slides 的过程中又重新审视了一下自己对函数式编程这个主题的了解深度, 感觉又有一些收获。
这次趁着端午假期的空闲,将讲座的内容尤其是 slides 当中使用的一些容易理解的配图整理出来, 形成这么一篇博客,希望能对读者有所帮助。
概览
一开始让我去讲函数式编程,其实我是拒绝的。老实说,科技界的很多术语的内涵其实一直比较模糊。 就拿函数式编程来说,它到底是什么、涵盖了多少内容其实不是一件容易界定的事情。况且, 函数式编程尽管已经有多年的发展历史,普通的程序员们对它的认识却还是参差不齐或深有误解。
其中可能是最大的误解之一可能就是认为函数式编程主要是前端届在使用的范式,在其它领域没有用武之地。 就连邀请我进行讲座的主办方,也是以这样一种认知为基础,想要我在前端的语境下来准备主题。 这是我使用 ES6 作为讲座中使用的编程语言的主要原因。尽管如此, 我准备的内容绝大部分其实跟前端技术的联系并不紧密,主要的内容有两个:
- 函数式编程的一些“奇技淫巧”,主要是闭包、惰性求值和 Y-Combinator
- 根据关于函数式编程在网络上最新的一些讨论,尤其是 Haoyi Li 老师的 《What’s functional programming all about》 这篇文章,浅谈了一些关于函数式编程本质的东西
在我准备的讲座当中还有一个有关 FP 在 React 当中体现的章节,因个人觉得不是特别重要, 在这篇文章当中就不赘述了。
Closure
Closure,也就是闭包,可以说是函数式编程基础当中的基础。闭包的存在体现了函数式编程的几个重要特点: 函数是编程语言的一等成员以及高阶函数的存在。
关于闭包,在圈内有两句著名的格言:
Objects are a poor man’s closures
以及
Closures are a poor man’s objects
这两句话据信都出自 MIT 早期的邮件列表当中一个著名的 Thread 《What’s so cool about Scheme?》。 肤浅地理解的话,这两句加起来其实表达了闭包和对象两种模型在某种程度上是同一的。
我们来看一下闭包是如何实现对象可以完成的工作的。一个最简单的例子可能是使用闭包来实现链表:
1 | let getNode = (value , next) => { |
getNode 函数返回了一个闭包,我们知道,闭包是一个保存了上层函数调用时的环境上下文的函数。
因此,我们传给getNode函数的两个参数value和next会被保存在闭包中。如下图所示:
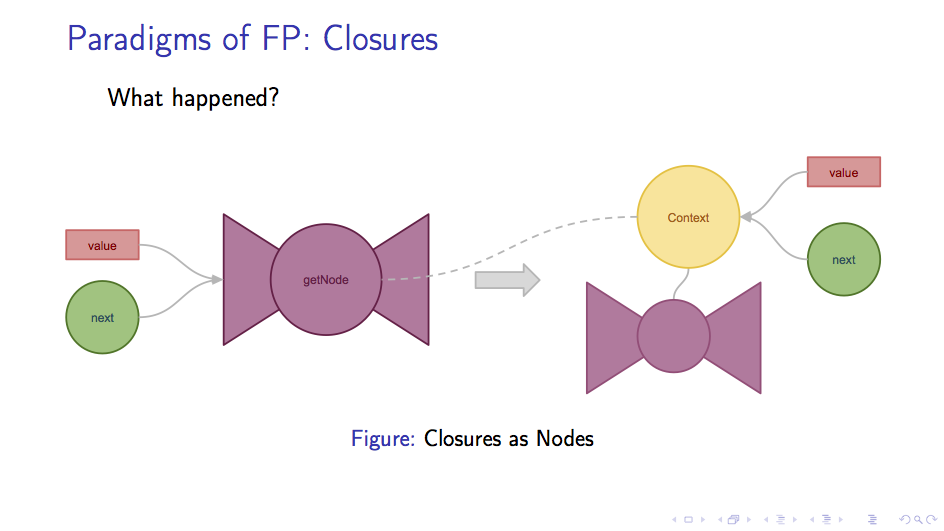
比如 C 的 struct 和 Java 的 class 中,获得一个对象的成员变量,往往是取内存地址的操作,
然而在使用闭包作为对象的时候,因为闭包本身就是个函数,我们是通过使用不同的参数调用闭包来获得不同的字段的。
譬如在这个例子里,传给闭包 true,函数会返回 value,反之则会返回 next。下图展示了这个过程:
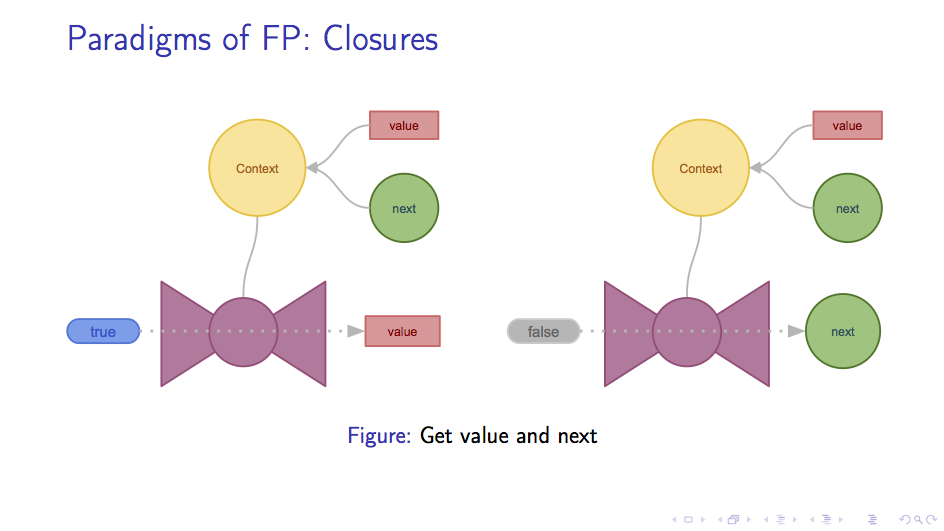
可以使用闭包获得值和指向下一个节点的指针之后,这个闭包就跟普通的链表节点没什么不同了。 我们可以像使用结构体那样使用它,只不过在取值和指针的时候是通过函数调用而不是直接的取字段的方法来完成的。
1 | let a = getNode(1, getNode(2, getNode(3, null))); |
一个更复杂的例子是实现链表反转,我们首先实现了一个 append 函数用来将一个节点追加到一个链表当中,
之后的 reverse 函数其实就是通过不断对自己递归地调用而完成工作的——尽管从时间复杂度上来看这个解决方案并不怎么有效,
然而它却是在完全没有对象系统和循环的前提下而实现的。
1 | let append = (n, v) => { |
其实,在很多 Lisp 里面的 cons、 car、 cdr 等函数,实际上就对应于上面例子当中的
getNode、 value、 next 三个函数。在一些实现里,更是直接用闭包来实现列表的。
Lazy Evaluation
在上面链表的例子之后,我们可以来看一下惰性求值的实现方法。譬如说, 我们想得到一个表示自然数这一个无穷序列的闭包。那么可能可以有如下代码:
1 | let naturalNumber = (n) => { |
表面上这个函数会无穷地递归自己,但是考虑到 a ? b : c 这样一个判断表达式当中,b 和 c
都只有当对应的条件满足之后才会被编译器求解,无限递归的情况并不会发生。
要理解上述函数如何产生自然数的序列。我们先参照上一章的形式,展示我们所得到的闭包的结构。
如下图所示,可以看到只有一个字段n被保存在上下文环境中:
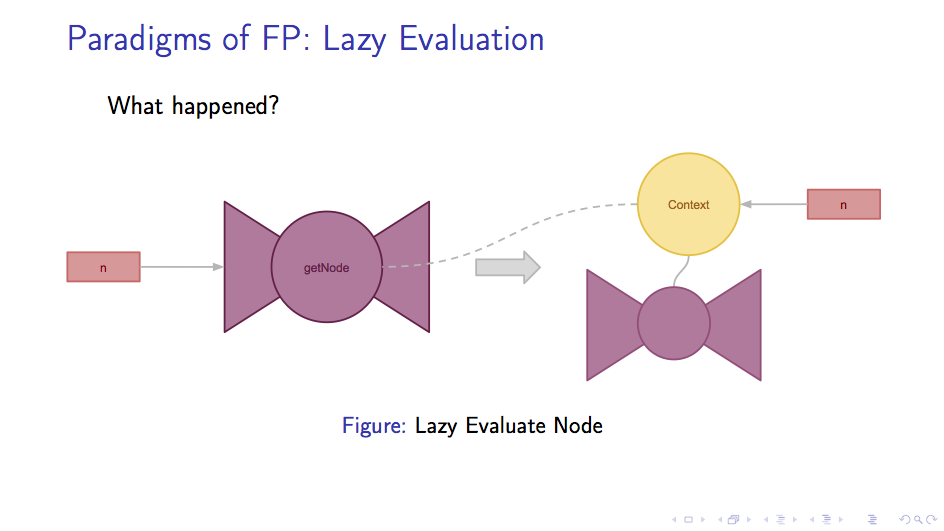
在取字段方面,使用 true 调用函数还是可以得到当前的值n,那么如果我们使用 false
来调用函数试图获得下一个节点会发生什么呢?
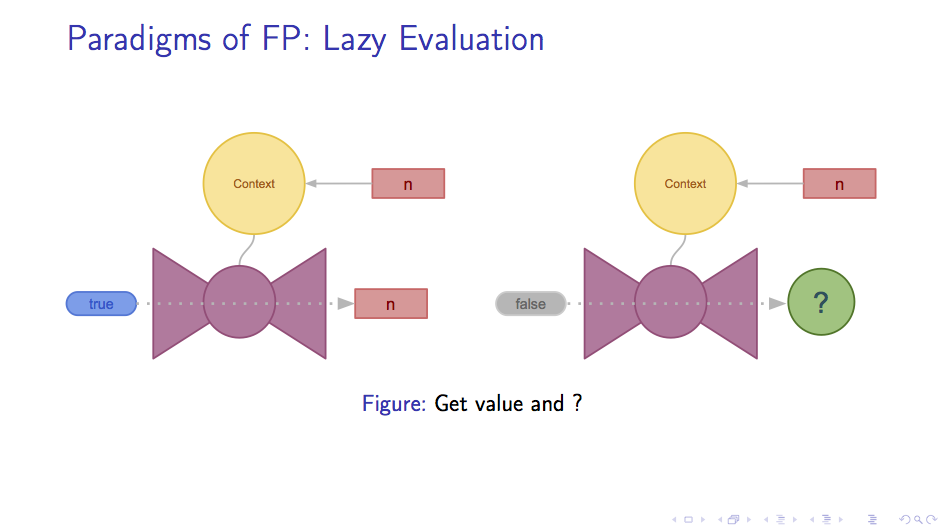
为了方便期间,我们将之前的整个闭包表示成一个小圆,把唯一的字段n填在小圆的中央。
下图展示了试图获取 next 的结果。可以看到,对包含字段n 的闭包取 next 会获得一个类似的闭包,
唯一的区别是字段的值变成了 n + 1。这个新的闭包实际上是对自己的递归调用,
也就是说,上述的函数通过递归定义的方式定义了自然数:
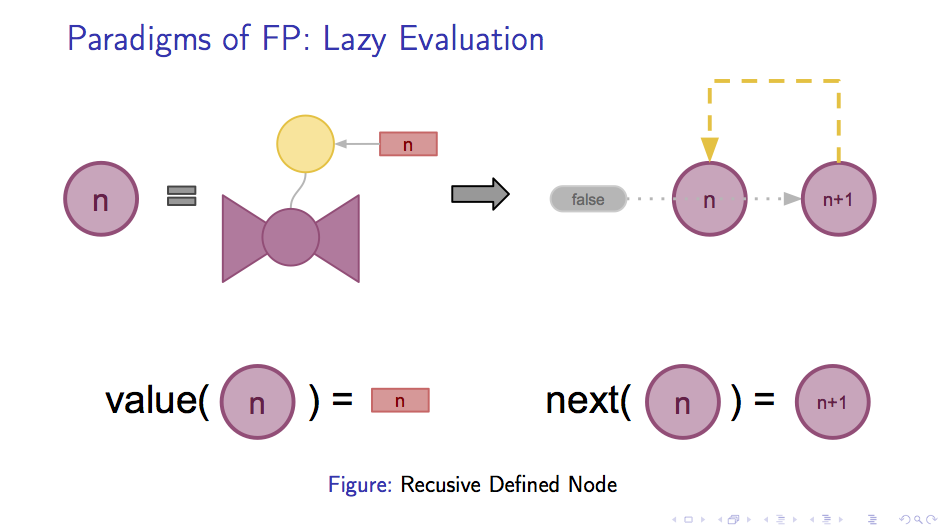
这样,我们就得到了一个惰性求值的表,这个链表虽然表示了无穷多数的序列,
但是并不会直接耗尽内存——新的值只有在需要的时候才被求解出来。上面的例子同样体现了接口或者鸭子类型的思想。
对于原来链表的value和next函数,因为我们新的naturalNumbers会返回同样接口的闭包,
因此我们不需要对这个惰性求值的表定义新的函数来取值和后继节点。原来的函数是直接可用的。
为了体现惰性求值方式的威力,我们来用 ES6 快速实现很多函数式编程语言都会给出的一个案例: Sieve of Eratosthenes, 也就是素数的筛法。很多语言在给出的相关例子对于初学者来说可能很难理解, 在这篇文章的稍后部分会使用图示的方法来辅助说明到底发生了什么。现在还是先看代码:
1 | let nextMatch = (seq, fn) => { |
在这里我们定义了三个方法,第一个函数找到当前序列当中第一个符合函数的匹配,
第二个函数将序列中不符合条件的元素过滤掉,最后一个函数就是我们的素数筛法实现。
可以看到,后两个方法采用了和 naturalNumbers 一样的惰性求值的方法。
他们会返回一个新的闭包,这个闭包服从我们之前的取值和取后继节点的接口,
因此我们可以像操作链表节点一样操作他们。
我们定义如下的take方法来从这样的一个惰性的表里取出若干的元素转换成普通链表,
这样我们就可以查看这些元素的内容。
1 | let take = (n, count) => { |
像下面这样调用sieve函数,我们就得到了所有素数的一种表示,
使用take来查看前五个元素,就会得到前五个素数的值。
1 | let primes = sieve(naturalNumber(2)); |
这到底是如何做到的呢?作为筛法,在这里是如何把之前筛出的素数保留下来从而再反过来用于筛选后面的素数的呢?
我们先来看函数第一次调用的时候的情况。因为我们将从 2 开始的自然数的惰性序列传给了 sieve 函数,
所以我们第一个得到的素数显然是 2:
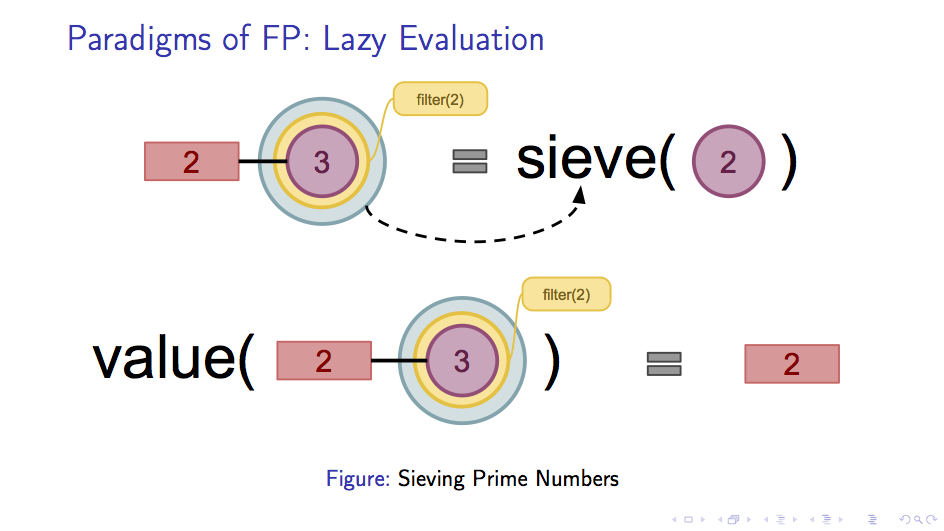
在这里,我们用在最外层的蓝色圆圈表示一层未求解的 sieve 函数,用filter(n)表示将n及其倍数都过滤掉的过滤函数。
可以看到,在最初的状态下,右边代表next的部分,sieve函数只求解了一层。这种情况下我们的自然数序列现在在n=3的状态,
filter也只有一层。
当我们试图取next从而使得右边的sieve函数被求值一层之后,返回的仍然是一个惰性求值的sieve函数,
只不过发生了两个变化:
3被从自然数序列当中取出filter(3)被叠加在filter(2)之上,形成了两层 filter 的情况
如下图所示:
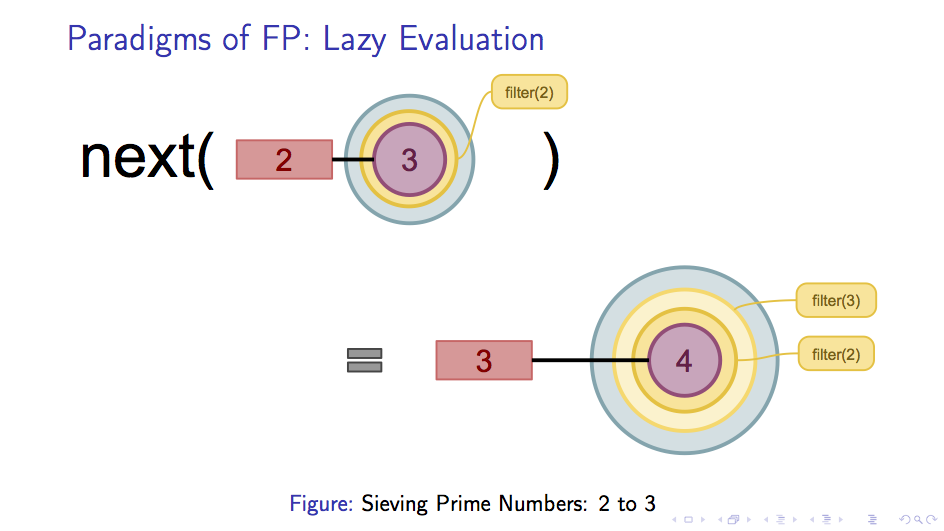
接下来再次取next情况也是类似的,譬如我们取出了一个数 p ,那么就会有一层新的filter(p)被加入到新的next表示当中。
当我们取出一个和数,因为他会被之前的某一层filter过滤掉,因此每次取出的p一定是素数。下面是取出5的时候的情况,
可以看到,之所以4没有被取出是因为被filter(2)过滤掉了。
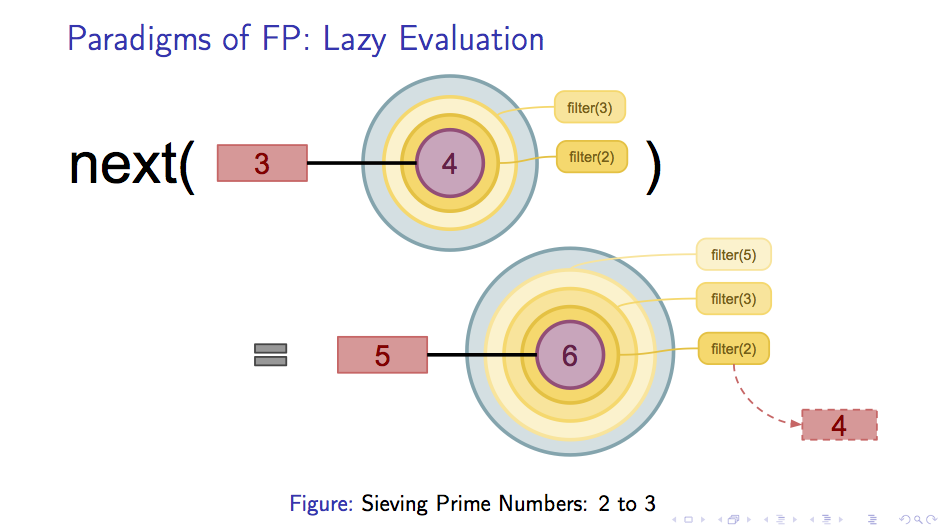
以上就是通过惰性求值实现素数筛法的原理。
可以看到,即使是使用 JavaScript,通过一些简单的定义和纯函数的构造方法, 我们只需要很少量的代码就可以实现惰性求值的列表。这也是将闭包作为对象的威力所在。 值得一提得是,《计算机程序的构造与解释》 一书中指出,Stream 其实就是惰性求值的表。 因此现在流行的很多流处理框架,如 ReactiveX、Spark 等实现的模型,其实就是从这里开始的。有些编程语言如 Haskell 等,默认就全局地使用惰性求值来处理列表。
Y-Combinator
提到 Y-Combinator,对于不了解函数式编程历史的人来讲,可能第一个想到的是硅谷著名的天使投资机构 YC和Hacker News。 其实,Y-Combinator 最早是由 Haskel Brooks Curry 提出的一个可以用于实现递归的组合子。
虽然Y-Combinator 在实际当中没有什么使用场景,但在网上有些人认为, 是否解了 Y-Combinator 是判断一个人对函数式编程是否真正入门的依据。 我觉得,了解 Y-Combinator 至少对理解计算理论和函数式编程的早期发展有很大帮助。 这反过来也会加深一个人对函数式编程本身内涵的理解。
我们从一个有趣的问题开始:如何只通过匿名函数实现递归?。
这个问题看似简单,其实却需要一些技巧才能解决。 如果你想要递归调用的函数没有名字,那么你又如何调用它呢?我们来看下面求阶乘的递归函数的例子。
1 | let fact = (n) => { |
可以看到,fact要递归调用自己,必须要有一个名字fact存在。容易想到,虽然函数本身是匿名的,
但是如果我把它传给另一个函数,让他作为另一个函数的参数存在,由于参数是有名字的,那这个函数是不是就是有名字的了呢?
1 | let F = (f) => { |
在这里,我们得到了一个函数
$$F:f\rightarrow f’$$
这个函数接收一个函数 $f$ 作为参数,返回另一个函数 $f’$。因为 $f’$ 是一个在内部调用 $f$ 的函数, 如果 $f’=f$,那么 $f’$ 就是一个自己递归调用自己的函数,也就是我们需要的求阶乘的递归函数。 给定一个$F$,我们怎么得到我们想要的 $f’$ 呢?在数学上,使得 $F(f)=f$ (即 $f=f’$) 的参数 $f$ 被称为 $F$ 的不动点。而下面的函数 $Y$ “恰好”总是能返回这样一个 $F$ 的不动点(即 $Y(F)=F(Y(F))$):
1 | let Y = (F) => { |
这样的 $Y$ 就被称为 Y-Combinator,它是由 Haskell Brooks Curry 最早发现的。
值得注意的是这个不动点 $f$ 是指 $F(f)$ 和 $f$ 这两个函数在他们所有参数的取值范围内每一个点的值都相同。 在数学上符合这个定义的两个函数是同一的,然而在我们的程序的执行过程当中 $F(f)$ 相较 $f$ 其实是一个新的函数。 接下来我们就可以使用一个表达式来调用我们的匿名递归函数了:
1 | (F => (x => F(v => x(x)(v)))(x => F(v => x(x)(v))))(f => (n => n == 1 ? 1 : n * f(n - 1)))(10) |
Y-Combinator 是建立在最早由 Alonzo Church 提出的 λ−calculus 的框架上的。λ−calculus 是一种和图灵机等价的计算模型。 最早作为解决可计算性问题的一个模型提出。Church 同时还提出了 Church Numerals (邱奇计数) 这种使用函数来表示自然数的表示方法。
此外,有三门编程语言以 Haskell Brooks Curry 命名,Curry 用作动词得到的 Currying 同时又翻译作柯里化, 也是在函数式编程当中非常重要的一个概念。
下面是函数式编程相比于命令式编程发展的历史示意图:

可以看到,从源头来说,函数式编程的起源非常早,第一门函数式编程语言 LISP 直接受到了 λ−calculus 的影响, 而 LISP 实际上是历史上第二门高级编程语言,早于 C 语言十几年。结合 Y-Combinator 的理论,我们其实可以看到:
- 函数式编程和计算数学理论联系非常紧密
- 函数式编程不光是把函数作为 First Class Member,实际上我们还可以把函数作为原料进行组合和变换,从而实现各种功能
- 函数式编程的起源非常早,也从来没有“最近”才火起来,更不是只可以应用于少量特定领域
The Core of Functional Programming
这一部分的内容主要是对 《What’s functional programming all about》 这篇文章的简单总结,建议各位读者尽量阅读原文。
谈到函数式编程,一个绕不过的话题还是函数式编程到底是什么?我们可以有如下观察:
- 从类型系统上来说,函数式编程语言既有静态类型(Haskell, Scala 等)又有动态类型(Scheme 等), 因此这一点并不是主要的判断标准
- 现在大多数编程语言都是多范式的,很多语言都支持高阶函数、闭包等特性,很有很多库实现了类似的范式, 而在所谓的函数式编程语言中,也可以写出命令式的风格,因此是否使用函数式编程语言编写代码不是函数式编程的判断标准
目前的一种我比较认同的观点是:
The core of Functional Programming is thinking about data-flow rather than control-flow
怎么理解上面这句话呢?一个例子是烘焙蛋糕,如果我们以控制流(Control-flow)的方式思考,大约就是像下图这样的一个菜谱

菜谱告诉了你要怎么一步一步地工作,从而制作出目标的产品。但是存在以下一些问题:
- 哪些步骤是可以并行的?如果由多个人同时参与,如何才能分工合作加快进度?
- 在这些步骤当中,哪些工具是共享的?如果想要互不干扰地分工合作,每种工具要准备多少?
- 如何从这个菜谱出发,设计可以应用于工厂批量处理的生产流程?每种原料应该以多少比例配置?
上面三个问题其实体现了现在的软件工程面临的几个重要的问题:并行性、并发同步和工程规模的膨胀。 读者可能在其他地方了解到,函数式编程在这几个方面都提供了较好的解决方案,因此越来越受这些领域的工程师的关注。 原因是什么呢?我们首先将上面的菜谱的每一条指令以输入、操作、输出三个部分着色

可以看到,每条指令其实都可以看作一次函数的调用。如果我们把最初的原料列出来, 并以这些原料在所有这些步骤所代表的函数当中流动的角度看问题,我们大抵可以得到下面这样的流程图
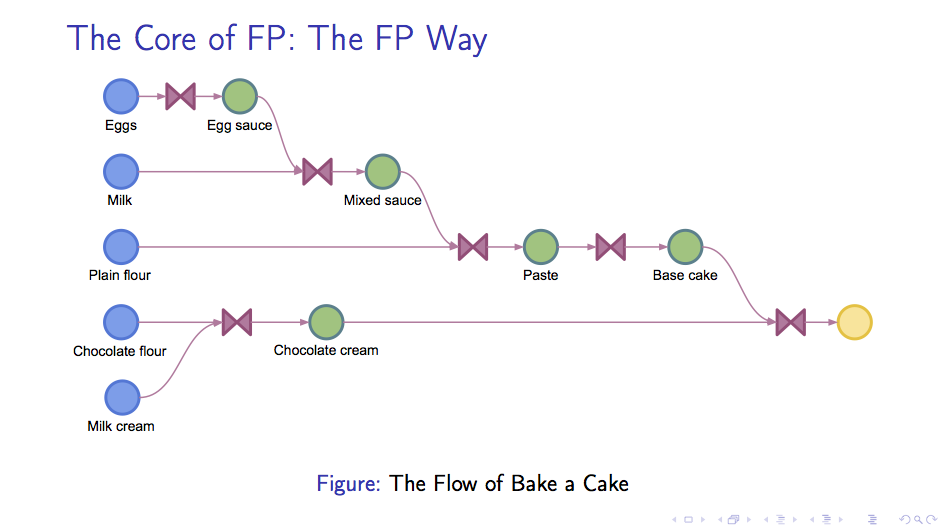
如果把蛋糕的原料看作数据,那么这种思考问题的角度就是以数据流(Data-flow)为中心的思考方式。 可以看到,这种方式恰好是函数式编程提倡的方式,它隐含的一些思想包括:
- 函数应该是没有副作用的, 函数的作用总是接收参数并返回结果,同样的参数应该返回同样的结果。 符合这样方式的函数调用很大程度上解决了函数的同步的问题(因为没有共享变量,函数的调用可以快速并发)
- 通过将函数串联起来实现功能,而不是维护一个对象的状态。在这种方式下, 所有的数据像水流一样在程序的各个部分快速流动,而不是存在某个对象来维护系统当前的状态
- 可以通过惰性求值将各个模块以 Flow 的形式组织起来,每个模块是一个功能单一且无状态的过程(服务), 从而可以实现大规模的软件工程
可以看到,目前比较热门的数据实时流处理(Spark Streaming, ReactiveX)、微服务架构、Docker 等技术都或多或少受到了这种思想的影响。
也许把所有这些 Dataflow 为中心思考问题的方法都归结到函数式编程的范畴当中有些夸张了, 但是函数式编程本身确实比其它地方更加强调这种思想。这也是我认为学习函数式编程最重要的意义: 通过应用函数式编程的思想来组织和架构软件,可以得到更加接近数据流思维方式的结构, 从而获得更好的并发性、鲁棒性和可扩展性。
总结
在这篇文章中,把我之前所做的 FP 分享的主要内容总结了一下。在准备这个分享的过程当中, 我自己收益良多。包括理清一些函数式编程语言的相互影响和继承关系,了解了从最早的计算理论开始的 FP 发展历史, 对一些函数式的常见范式如惰性求值的实现的理解也更加清晰了。
另外还需要总结的一点是进行公开技术分享方面的经验。那就是在准备内容的时候一定要确认好听众的接受能力和平均水平, 尽管这次我觉得自己准备的内容已经算是相当入门的水准了,然而绝大部分听众接受起来还是有点困难。 这一方面表明了 FP 在平均的程序员当中的普及水平还是比较初级的,另一方面也是自己立意太高导致的。
近期我还在 SHLUG 的月度分享当中进行了一次 Git 中级知识的技术讲座, 跟着次讲座恰好相反——我准备的内容略显浅显。关于这次 Git 的讲座也有很多有意思的知识,回来也将会再总结为一篇博客。 敬请期待。